
Wat doet de tool?
De tool detecteert groepen waarvoor een algoritme of AI-systeem afwijkend presteert, wat mogelijk zou kunnen duiden op ongelijke behandeling. Naar deze vorm van monitoring wordt verwezen als anomaliedetectie. Voor het detecteren van afwijkende partonen maakt de tool gebruik van clustering om datapunten te groeperen (in clusters). De tool heeft geen beschermde kenmerken nodig van gebruikers, zoals geslacht, nationaliteit of etniciteit, om afwijkingen te detecteren. De variabele aan de hand waarvan onderscheid wordt bepaald kan handmatig worden gekozen en wordt naar verwezen als de bias variabele.
Welke uitkomsten geeft de tool?
De tool identificeert groepen (clusters) waarvoor de prestaties van het algoritme systematisch afwijken. Het cluster met de meest afwijkende bias variabele wordt uitgelicht en er wordt een bias analyse-rapport gegenereerd dat als PDF kan worden gedownload. Ook kunnen alle geïdentificeerde groepen (clusters) als .json-bestand worden gedownload. Daarnaast biedt de tool visualisaties van de resultaten, zodat domeinexperts de gevonden afwijkingen nader kunnen onderzoeken. Een voorbeeld is hieronder te zien.
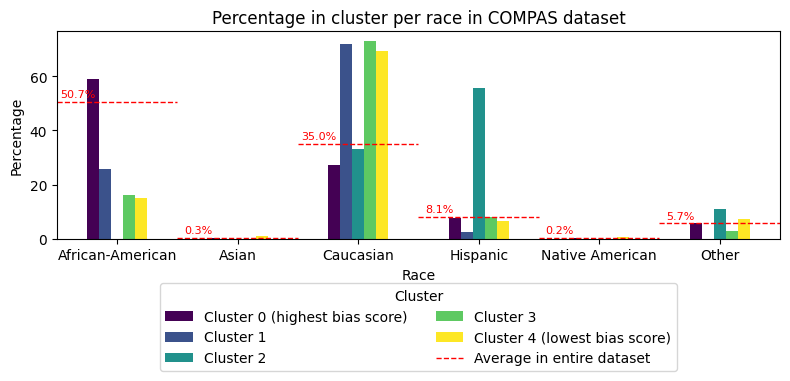
Welke data kan worden verwerkt?
De tool verwerkt data in tabel-formaat, dat enkel uit numerieke of categorische waarden bestaat. Eén kolom moet worden geselecteerd als bias variabele. Deze kolom mag enkel uit categorische waarden bestaan. De gebruiker dient aan te aangeven of een hoge of lage waarde van de bias variabele beter is. Voorbeeld: als je kijkt naar foutpercentages, zijn lagere waarden beter; voor nauwkeurigheid zijn hogere waarden beter. De tool bevat ook een demo dataset die je kunt gebruiken door op “Demo dataset” te klikken.
Voorbeeld van numerieke dataset:
| Leeftijd | Inkomen | ... | Aantal auto's | Geselecteerd voor controle |
|---|---|---|---|---|
| 35 | 55.000 | ... | 1 | 1 |
| 40 | 45.000 | ... | 0 | 0 |
| ... | ... | ... | ... | ... |
| 20 | 30.000 | ... | 0 | 0 |
Is mijn data veilig?
Ja! Je data blijft op je eigen computer en verlaat de omgeving van je organisatie niet. De tool werkt in je browser en gebruikt de rekenkracht van je lokla apparaat om de data te analyseren. Deze aanpak, ‘local-only’ genaamd, zorgt ervoor dat er geen data met cloudproviders of andere derde partijen wordt gedeeld – ook niet met Algorithm Audit. Meer informatie over deze local-only architectuur vind je hieronder. Instructies om local-only tools binnen je organisatie te hosten zijn te vinden op Github.
Gebruik de tool hier beneden ⬇️
Welke stappen doorloopt de tool?
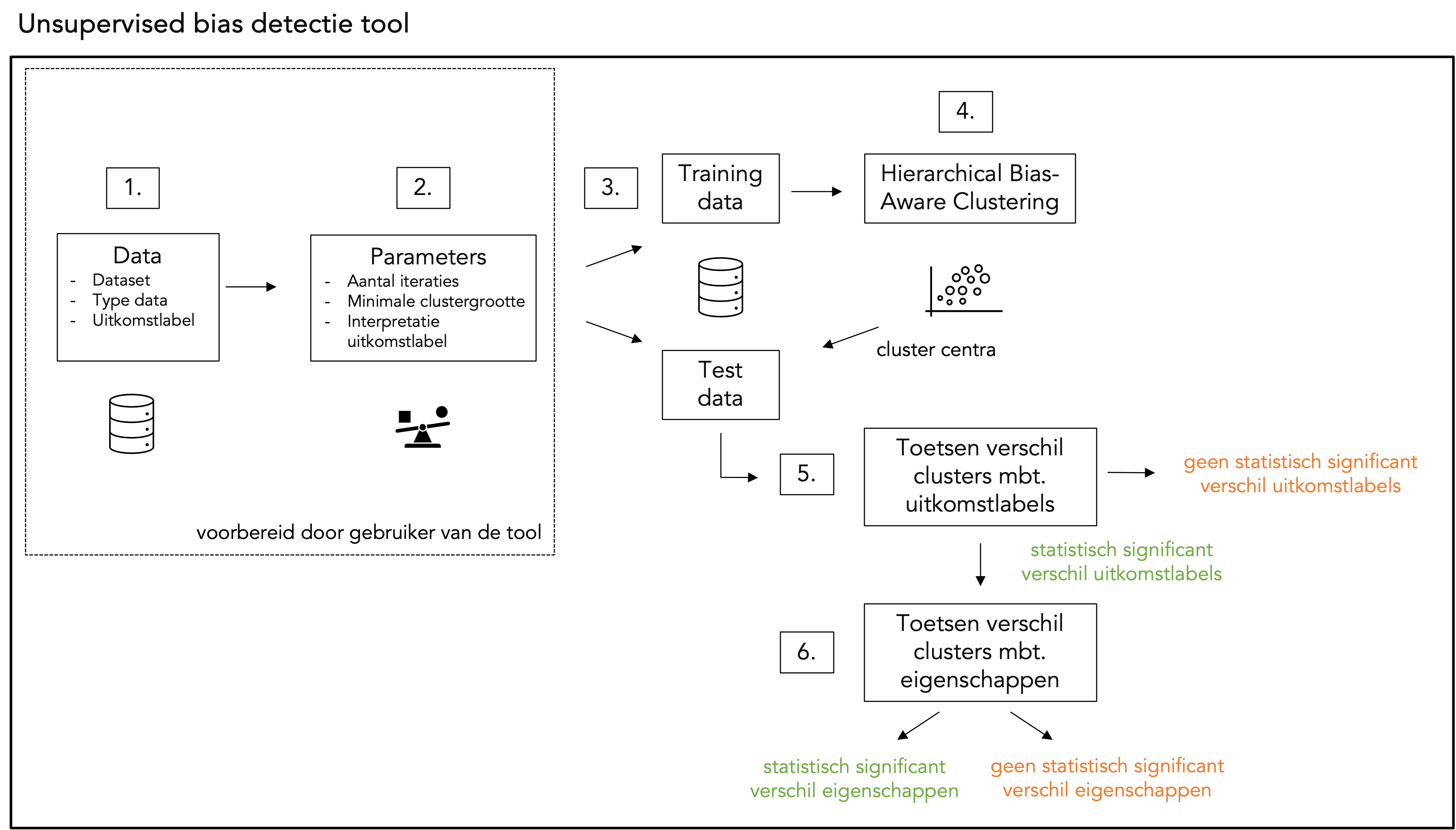
De unsupervised bias detectie tool voert de volgende stappen uit:
Vereiste voorbereidingen door de gebruiker:
Stap 1. Data: de gebruiker dient de volgende aspecten van de te verwerken data voor te bereiden:
- Dataset: De data moet worden aangeleverd in tabelvorm. Eventuele ontbrekende waarden dienen te worden verwijderd of vervangen.
- Type data: Alle kolommen, behalve de bias variabele-kolom, moeten hetzelfde datatype hebben, bijvoorbeeld allemaal numeriek of allemaal categorisch. De gebruiker geeft aan of numerieke of categorische data worden verwerkt.
- Bias variabele: Er moet een kolom uit de dataset worden geselecteerd als
bias variabele, welke categorisch moet zijn. In stap 4 wordt op basis van deze categorische waarden clustering uitgevoerd. Voorbeelden zijn: “aangewezen als hoog risico”, “foutpercentage” of “geselecteerd voor controle”.
Stap 2. Hyperparameters: de gebruiker kiest de volgende hyperparameters:
- Iteraties: Hoe vaak de data mogen worden gesplitst in kleinere clusters; standaard zijn 3 iteraties ingesteld.
- Minimale clustergrootte: Hoeveel datapunten de gevonden clusters minimaal moeten bevatten; standaard is dit 1% van het aantal rijen in de dataset. Meer uitleg over een geïnformeerde keuze voor de minimale clustergrootte is te vinden in sectie 3.3 van onze wetenschappelijke paper.
- Interpretatie bias variabele: Hoe de bias variabele geïnterpreteerd moet worden. Bijvoorbeeld: als foutpercentage of misclassificaties als bias variabele worden gekozen, is een lagere waarde beter, omdat het doel is fouten te minimaliseren. Als nauwkeurigheid of precisie als bias variabele wordt gekozen, is een hogere waarde beter, omdat het doel is de prestaties te maximaliseren.
Uitgevoerd door de tool:
Stap 3. Train-test data: De dataset wordt opgesplitst in een train- en testsubset, volgens een 80-20 verhouding.
Stap 4. Hierarchisch Bias-Aware Clustering (HBAC): Het HBAC-algoritme (hieronder toegelicht) wordt toegepast op de train dataset. De centra van de gevonden clusters worden opgeslagen en later gebruikt om clusterlabels toe te wijzen aan datapunten in de test dataset.
Stap 5. Toetsen van verschillen tussen clusters mbt. bias variabele: Statistische hypothesetoets wordt uitgevoerd om te bepalen of de bias variabele significant verschilt in het meest afwijkende cluster ten opzichte van de rest van de dataset. Hiervoor wordt een eenzijdige Z-toets gebruikt om de gemiddelden van de bias variabelen te vergelijken middels de volgende hypothesetoets:
H_0: geen verschil in bias variable tussen het meest afwijkende cluster en de rest van de dataset
H_A: verschil in bias variable tussen het meest afwijkende cluster en de rest van de dataset.
Stap 6. Toetsen van verschillen tussen cluster mbt. eigenschappen: Indien een statistisch significant verschil in bias variabele wordt gevonden tussen het meest afwijkende cluster en de rest van de dataset, worden de verschillen in eigenschappen (tussen het meest afwijkende cluster en de rest van de dataset) onderzocht. Ook hiervoor wordt statistische hypothesetoetsen gebruikt, namelijk een t-toets wanneer numerieke data en de Pearson 𝜒²-toets wanneer categorische data worden verwerkt. Bij het uitvoeren van meerdere hypothesetoetsen wordt Bonferroni-correctie toegepast. Meer informatie hierover kan worden gevonden in sectie 3.4 van onze wetenschappelijke paper.
Een schematisch overzicht van bovenstaande stappen wordt hieronder weergegeven.
Hoe werkt het clustering algoritme?
Het Hierarchisch Bias-Aware Clustering (HBAC) algoritme identificeert clusters in de aangeleverde dataset op basis van een door de gebruiker gekozen bias variabele. Het doel is om clusters te vinden met een lage variatie in bias variabele binnen elk cluster, terwijl de variatie tussen clusters juist hoog is. HBAC vindt iteratief clusters in de data met behulp van k-means clustering (voor numerieke data) of k-modes clustering (voor categorische data). Voor de eerste split neemt HBAC de volledige dataset en splitst deze in twee clusters. Cluster C – met de hoogste standaarddeviatie van de bias variabele – wordt geselecteerd. Vervolgens wordt cluster C opgesplitst in twee kandidaat-clusters C' en C''. Als het gemiddelde van de bias variabele in een van de kandidaat-clusters hoger is dan het gemiddelde in C, wordt het kandidaat-cluster met de hoogste bias variabele geselecteerd als nieuw cluster. Dit proces herhaalt zich totdat het maximale aantal iteraties (max_iteraties) is bereikt of het resulterende cluster niet meer voldoet aan de minimale grootte (n_min). De pseudo-code van het HBAC-algoritme is hieronder weergegeven.

Het HBAC-algoritme is geïntroduceerd door Misztal-Radecka en Indurkhya in een wetenschappelijk artikel gepubliceerd in Information Processing and Management (2021). Onze implementatie van het HBAC-algoritme bouwt hierop voort door aanvullende methodologische checks toe te voegen om echte signalen van ruis te onderscheiden, zoals sample splitting, het statistisch toetsen van hypotheses en het meten van clusterstabiliteit. De implementatie van het algoritme door Algorithm Audit is te vinden in het unsupervised-bias-detection pip package.
Hoe moeten de resultaten van de tool worden geïnterpreteerd?
Het HBAC-algoritme maximaliseert het verschil in bias variabele tussen clusters. Om te voorkomen dat er ten onrechte wordt geconcludeerd dat er ongewenste afwijkingen zijn in het onderzochte besluitvormingsproces terwijl die er niet zijn, wordt: 1) de dataset gesplitst in train- en testdata; en 2) toetsen we hyptotheses. Als een statistisch significante afwijking wordt gedetecteerd, vormt de uitkomst van de tool een startpunt voor domeinexperts om de geïdentificeerde afwijkingen in het besluitvormingsproces te beoordelen.
Web app – Unsupervised bias detectie tool
De broncode van unsupervised bias detectie door middel van het HBAC-algoritme is beschikbaar op Github en als pip package:
pip install unsupervised-bias-detection.De achitectuur om web apps local-only te gebruiken is ook beschikbaar op Github.

De unsupervised bias detectie tool is in de praktijk toegepast om een risicoprofileringsalgoritme van de Dienst Uitvoering Onderwijs (DUO) te auditen. Ons team heeft deze casus uitgewerkt in een wetenschappelijke paper. De tool identificeerde proxies voor studenten met een niet-Europese migratieachtergrond in het risicoprofileringsalgoritme, specifiek opleidingsniveau en de afstand tussen het adres van de student en dat van hun ouder(s). Afwijkingen in het controleproces hadden dus ook gevonden kunnen worden als CBS-data over de herkomst van studenten niet beschikbaar was geweest. De resultaten worden ook beschreven in Appendix A van het onderstaande rapport. Dit rapport is op 22-05-2024 naar de Tweede Kamer gestuurd.
Wat is local-only?
Local-only is het tegenovergestelde van cloud computing: de data wordt niet geüpload naar derden, zoals cloudproviders, en wordt verwerkt door je eigen computer. De data die aan de tool wordt gekoppeld, verlaat je computer of de omgeving van je organisatie dus niet. De tool is privacyvriendelijk omdat de data binnen bestaande bevoegdheden verwerkt kan worden en niet gedeeld hoeft te worden met nieuwe partijen. De unsupervised bias detectie tool kan ook lokaal binnen je organisatie worden gehost. Instructies, inclusief de broncode van de tool, zijn te vinden op Github.
Overzicht van local-only architectuur
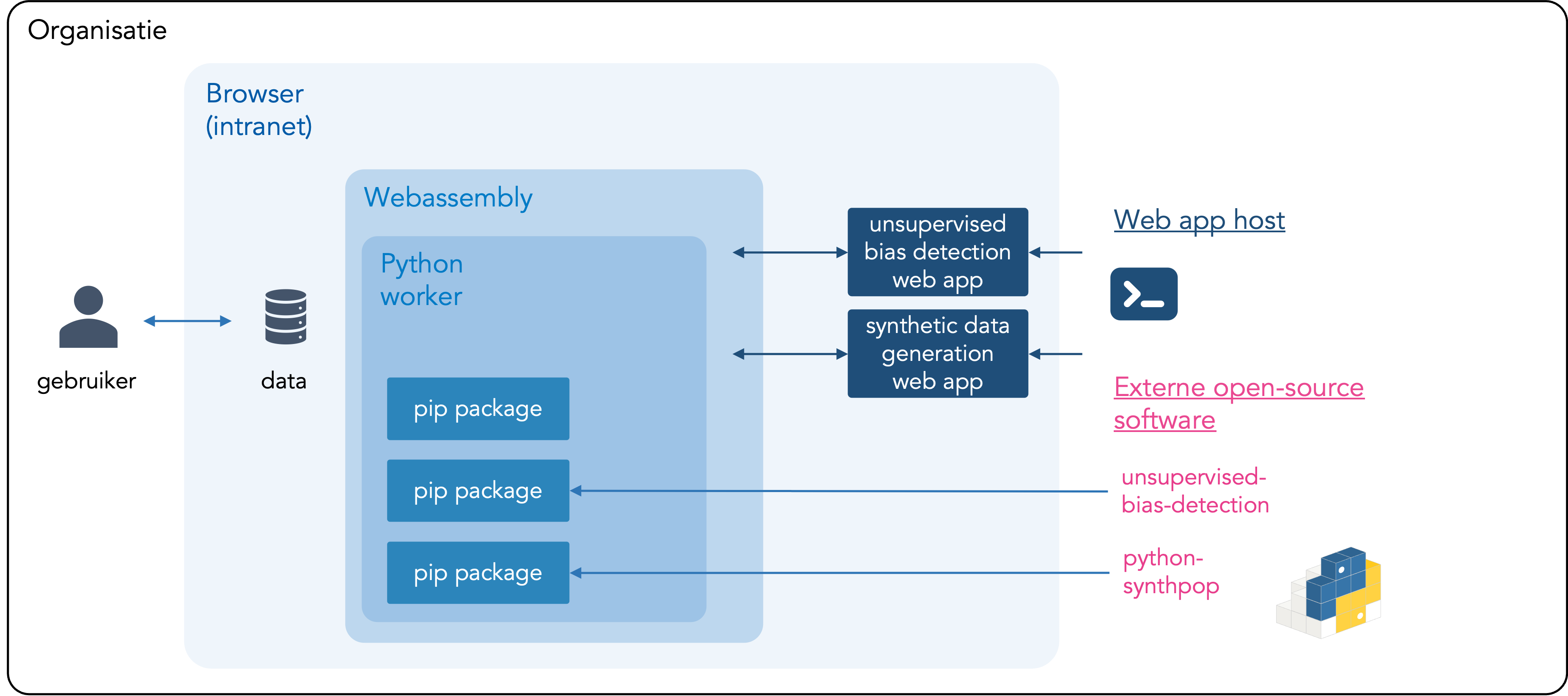
Explainer – Local-only tools voor AI validatie
Deze tool is ontwikkeld met steun van publieke en filantropische organisaties.

Innovatiebudget Ministerie van Binnenlandse Zaken
Beschrijving
In samenwerking met de Dienst Uitvoering Onderwijs (DUO) en het Ministerie van Binnenlandse Zaken heeft Algorithm Audit deze tool ontwikkeld en getest in de periode juli 2024 tot juli 2025 met ondersteuning van Innovatiebudget, een jaarlijkse competitie georganiseerd door het Ministerie van Binnenlandse Zaken. De voortgang van het project werd gedeeld tijdens een bijeenkomst op 13-02-2025.


SIDN Fonds
Beschrijving
In 2024 ondersteunde het SIDN Fonds Algorithm Audit bij het ontwikkelen van een eerste demo van de unsupervised bias detectie tool.
De tool heeft prijzen ontvangen en wordt ondersteund door verschillende belanghebbenden, waaronder maatschappelijke organisaties, vertegenwoordigers uit de industrie en academici.

Finalist Stanford’s AI Audit Challenge 2023
Beschrijving
Onder de naam Joint Fairness Assessment Method (JFAM) is de unsupervised bias detectie tool geselecteerd als finalist voor Stanford’s AI Audit Competition 2023.
OECD Catalogue of Tools & Metrics for Trustworthy AI
Description
De unsupervised bias detectie tool maakt deel uit van de Catalogue of Tools & Metrics for Trustworthy AI.
Belangrijkste punten over de unsupervised bias detectie tool:
- Kwantitatieve-kwalitatieve onderzoeksmethode: Data-gedreven onderzoek naar bias ter ondersteuning van delibartief en context-afhankelijk oordeel van domeinexperts;
- Unsupervised bias detectie: Vereist geen toegang tot bijzondere persoonsgegevens (unsupervised learning);
- Anolamiedetectie: Schaalbare methode gebaseerd op statische analyse;
- Detecteert complexe bias: Identificeert groepen die structureel afwijkend worden behandeld en geeft een beschrijving van deze groepen, in staat intersectionele bias te detecteren;
- Model-agnostic: Werkt voor alle algoritmen en AI-systemen;
- Open-source en zonder winstoogmerk: Gebruiksvriendelijke en gratis te gebruiken voor de gehele AI auditing gemeenschap.




