
Wat is synthetische data?
Synthetische data is artificiële data die de op groepsniveau de statistische kenmerken van de originele dataset nabootst zonder dat de data persoonsgegevens bevat.
Welke data kan worden verwerkt?
De tool verwerkt alle data in tabelvorm. Het type data (numeriek, categorisch, tijd, etc.) en ontbrekende waarden worden automatisch gedetecteerd. De gebruiker heeft verschillende opties om ontbrekende waarden te verwerken. Meer informatie over de omgang met missende waarden wordt in de tool gedeeld.
Wat is de uitkomst van de tool?
De tool genereert synthetische data. Een evaluatierapport van de gegenereerde data, inclusief verschillende evaluatiemetrieken, wordt automatisch opgesteld en kan als pdf worden gedownload. De synthetische data kan worden gedownload in .csv- en .json-formaat.
Welke methoden voor synthetische datageneratie worden ondersteund?
Gebruikers kunnen momenteel kiezen uit twee methoden voor het genereren van synthetische data:
- Classification And Regression Trees (CART); en
- Gaussian Copula (GC).
Standaard wordt CART gebruikt. CART produceert synthetische data van goede kwaliteit voor uiteenlopende soorten data, maar werkt mogelijk minder goed bij datasets met categorische variabelen met meer dan 20 categorieën. GC wordt in die gevallen aanbevolen. De tool bevat een demo-dataset waarvoor output wordt gegenereerd. Gebruik de knop ‘Probeer het uit’.
Is mijn data veilig?
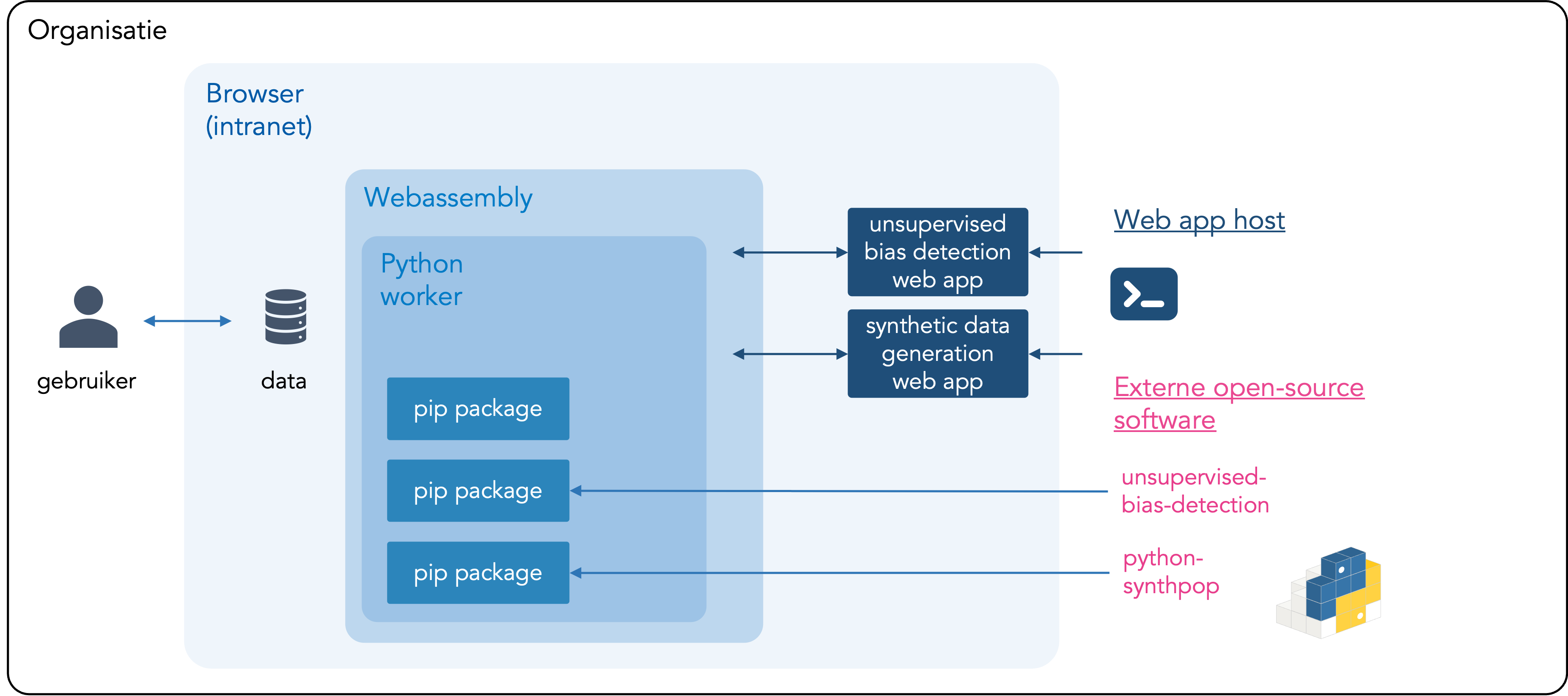
Ja! Je data blijft op je eigen computer en verlaat de omgeving van je organisatie niet. De tool werkt in je browser en gebruikt de rekenkracht van je lokla apparaat om de data te analyseren. Deze aanpak, ‘local-only’ genoemd, zorgt ervoor dat er geen data met cloudproviders of anderen wordt gedeeld. Meer informatie over deze local-only architectuur vind je hieronder. Instructies om local-only tools binnen je organisatie te hosten zijn te vinden op Github.
Probeer de tool hieronder uit ⬇️
De tool voor synthetische data generatie doorloopt de volgende stappen:
Benodigdheden van de gebruiker:
De gebruiker dient de volgende aspecten voor te bereiden:
- Dataset: Alleen categorische, numerieke of tijdsdata kunnen worden verwerkt. Datasets mogen maximaal 8 kolommen bevatten, dienen een header te hebben met kolomnamen en hoeven geen index-kolom te hebben.
- Methode: Standaard wordt de CART-methode gebruikt om synthetische data te genereren. CART levert doorgaans synthetische data van hoge kwaliteit, maar werkt mogelijk minder goed bij datasets met categorische variabelen met meer dan 20 categorieën. Gebruik in dat geval Gaussian Copula.
- Aantal synthetische datapunten: Aantal synthetische datapunten die door de tool worden gegenereerd. Vanwege de rekencapaciteit van browser-gebaseerde datageneratie is het maximum ingesteld op 5.000.
Uitgevoerd door de tool
De volgende stappen worden door de tool uitgevoerd:
Stap 1. Detecteren van datatypes:
De tool detecteert het type data voor elke kolom van de gekoppelde dataset (numerieke, categorische of tijdsdata).
Stap 2. Omgang met missende data:
- Missing at Random (MAR): De kans dat data ontbreekt hangt samen met de waargenomen data, maar niet met de ontbrekende data zelf. Het ontbreken kan worden voorspeld door andere variabelen in de dataset. Voorbeeld: toetsresultaten van studenten ontbreken, maar het ontbreken hangt samen met hun aanwezigheid. In dit scenario worden missende waarden vervangen door schattingen.
- Missing Not at Random (MNAR): De kans dat data ontbreekt hangt samen met de ontbrekende data zelf. Er is een patroon in het ontbreken van waarden dat samenhangt met de niet-waargenomen data. Voorbeeld: patiënten met ernstigere symptomen rapporteren deze minder vaak, waardoor ontbrekende data samenhangen met de ernst van de symptomen. Ook in dit scenario worden missende waarden vervangen door schattingen.
- Missing Completely at Random (MCAR): De kans dat data ontbreekt is volledig onafhankelijk van zowel waargenomen als niet-waargenomen data. Er is geen systematisch patroon. Voorbeeld: Een respondent slaat per ongeluk een vraag over door een drukfout. In dit scenario worden missende waarden verwijderd.
Meer informatie over concepten MCAR, MAR en MNAR kan worden gevonden in het boek Flexible Imputation of Missing Data van prof. Stef van Buuren, Universiteit Utrecht.
Stap [ongenummerd] Pre-verwerking:
Alle data worden omgezet naar numeriek formaat met behulp van LabelEncoder voor categorische kolommen met minder dan 10 unieke waarden, OneHotEncoder voor minder dan 50 unieke waarden en FrequencyEncoding voor overige gevallen. Voor numerieke data wordt StandardScaler gebruikt.
Stap 3. Synthese methode
- CART: De CART-methode (Classification and Regression Trees) genereert synthetische data door patronen te leren uit de echte data via een beslisboom die op basis van kenmerken data splitst in homogene groepen. Voor numerieke data worden gemiddelden voorspeld, voor categorische data de meest voorkomende categorie. Op basis hiervan worden nieuwe synthetische datapunten gegenereerd/gesampled.
- Gaussian Copula: Gaussian Copula werkt in twee stappen: 1. De echte data worden getransformeerd naar een uniforme verdeling. Correlaties tussen variabelen worden gemodelleerd met een multivariate normale verdeling (de Gaussian copula); en 2. Synthetische data worden gegenereerd door te sampelen uit deze copula en de samples terug te transformeren naar de oorspronkelijke verdelingen.
Stap [ongenummerd] Post-verwerking:
De gecodeerde data worden teruggezet naar het oorspronkelijke formaat.
Stap 4. Evaluatie:
De gegenereerde synthetische data worden op verschillende manieren geëvalueerd.
Step 4.1 Visualisatie:
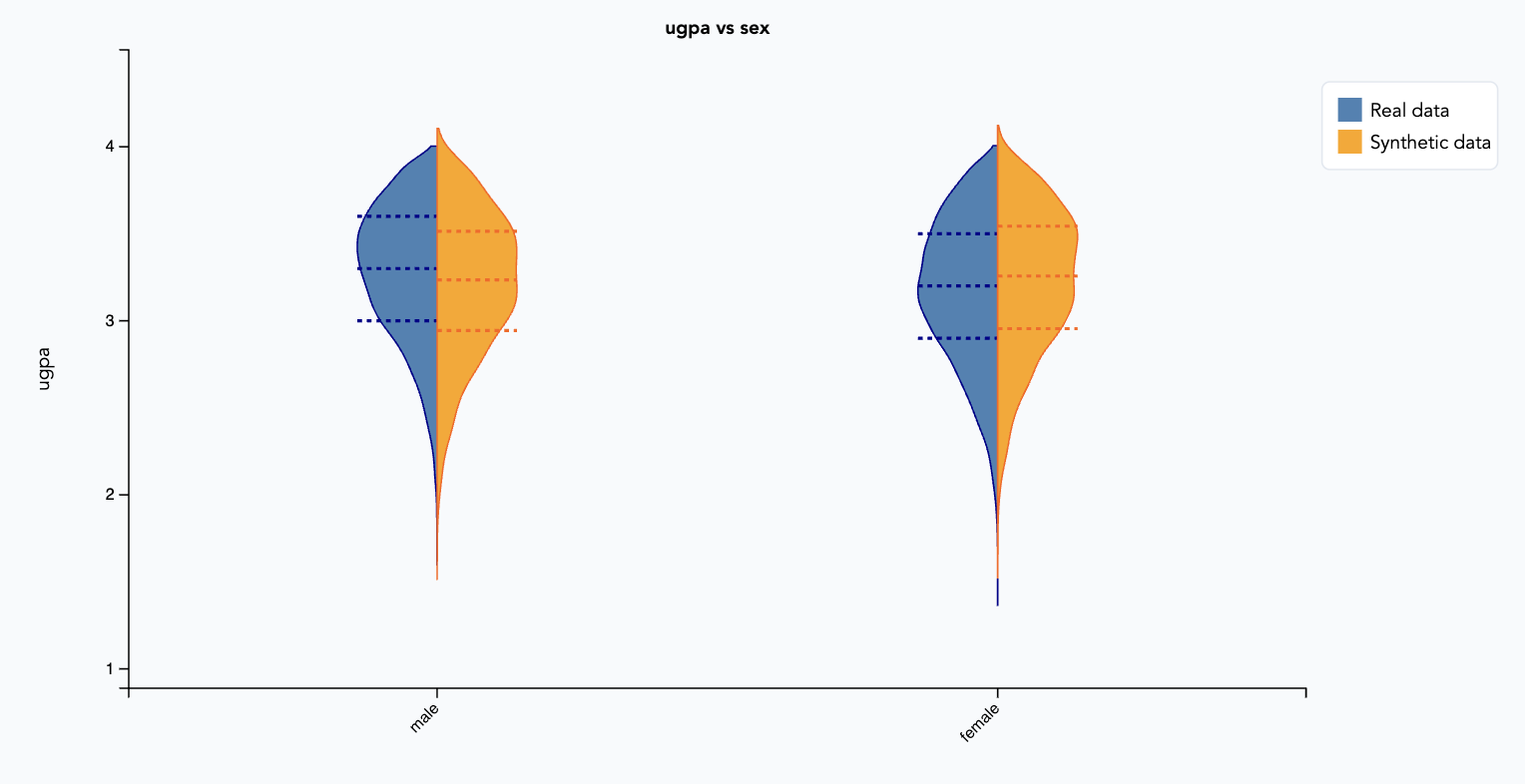
Univariate en bivariate grafieken worden gemaakt om de gegenereerde synthetische data te vergelijken met de echte data. Voor categorische variabelen worden staafdiagrammen getoond. Voor een combinatie van numerieke en categorische variabelen wordt een viool-plot gemaakt. Voor numerieke variabelen wordt een LOESS-plot getoond. In alle gevallen geldt: de synthetische data is van hoge kwaliteit als de verdelingen van de synthetische data overeenkomen met die van de echte data.
Stap 4.2 Diagnostisch rapport:
Voor elke kolom worden diagnostische resultaten bepaald voor de kwaliteit van de gegenereerde synthetische data. De gebruikte metrieken zijn afhankelijk van het datatype.
Diagnostische resultaten:
- Overeenkomst ontbrekende waarden: Vergelijkt of het aandeel missende waarden in de synthetische data gelijk is aan dat in de echte data;
- Bereik dekkend: Bepaalt per kolom of synthetische data het volledige bereik van waarden uit de echte data dekt;
- Grens eerbiediging: Bepaalt per kolom of synthetische data binnen de minimum- en maximumwaarden van de echte data blijven. Geeft het percentage rijen synthetische data dat binnen de grenzen valt;
- Statistische overeenkomst: Vergelijkt per kolom gemiddelde, standaarddeviatie en mediaan tussen echte en synthetische data;
- Kolmogorov–Smirnov (KS) complement: Meet het maximale verschil tussen de cumulatieve distributiefuncties (CDF’s) van numerieke kolommen in de synthetische en echte dataset.
Voor categorische kolommen worden de volgende metrieken berekend:
- Overeenkomst ontbrekende waarden: Vergelijkt of het aandeel missende waarden in de synthetische data gelijk is aan dat in de echte data;
- Categorie dekking: Bepaalt per kolom of de synthetische data alle categorieën uit de echte data bevat;
- Categorie eerbiediging: Bepaalt per kolom of synthetische data dezelfde categorieën bevat als de echte data;
- Totale variatie (TV) complement: Meet het maximale verschil tussen de cumulatieve distributiefuncties (CDF’s) van categorische kolommen in de synthetische en echte dataset.
💯 Bij goede kwaliteit synthetische data liggen alle waarden in de buurt van de 1.0, maar zeker hoger dan 0.85.
Correlatiematrix:
De één-op-één correlaties tussen variabelen in de synthetische en echte data worden berekend, wat de sterkte en richting van hun lineaire relaties aangeeft. De correlatiematrix van de gegenereerde synthetische en echte data dienen grofweg dezelfde patronen te hebben.
Effectiviteitsmetrieken:
Effectiviteitsmetrieken worden gebruikt om de kwaliteit en bruikbaarheid van synthetische data te beoordelen door te meten hoe goed een regressie- en classificatiemodel, getraind op synthetische data, presteert in vergelijking met modellen die op echte data zijn getraind.
Voor regressie (wanneer de doelvariabele numeriek is) worden de volgende metrieken berekend:
- Mean squared error (MSE): de gemiddelde kwadratische afwijking tussen voorspelde en werkelijke waarden, waarmee de nauwkeurigheid van de voorspellingen wordt gekwantificeerd en grotere fouten zwaarder worden bestraft;
- Mean absolute error (MAE): de gemiddelde absolute afwijking tussen voorspelde en werkelijke waarden, wat een directe maat geeft voor de nauwkeurigheid van het model zonder grote fouten extra te benadrukken;
- R² score: geeft aan in hoeverre de voorspellingen van het model overeenkomen met de werkelijke data door het aandeel verklaarde variantie in de doelvariabele te meten.
Voor classificatie (wanneer de doelvariabele categorisch is) worden de volgende metrieken berekend:
- Accuracy score: meet het aandeel correct voorspelde gevallen ten opzichte van het totaal, en geeft zo een algemene beoordeling van de prestaties van het classificatiemodel;
- Gewogen F1-score: het harmonisch gemiddelde van precisie en recall, berekend per klasse en gewogen naar het aantal echte gevallen per klasse, wat een metriek biedt voor datasets met ongelijke klassenverdeling.
Privacy metriek:
De onthullings beschermings metriek meet het aandeel synthetische datapunten die te veel lijkt op echte datapunten (binnen een vooraf gedefinieerde drempelwaarde), wat een risico op herleidbaarheid naar persoonsgegevens vormt. Een lage waarde van deze metriek duidt op een goede bescherming tegen het onbedoeld prijsgeven van persoonsgegevens.
Step 5. Download:
De gegenereerde synthetische data kan worden gedownload als csv- en json-bestand. De evaluatie volgens bovenstaande metrics kan als evaluatierapport in pdf worden gedownload.
Documentatie
Meer documentatie over de tool en onderliggende SDG methoden kunnen worden gevonden op Github.
Synthetische data generatie tool
De broncode van de synthetische data generatie methoden zijn beschikbaar op Github en als pip package:
pip install python-synthpop.De achitectuur om web apps local-only te gebruiken is ook beschikbaar op Github.
Bij het auditeren van algoritme-gedreven besluitvormingsprocessen is een van de meest prangende vragen de representativiteit van de brondata. Privacy vormt echter een obstakel bij het delen van data met externe partijen om de representativiteit van de data te onderzoeken. Zonder toegang tot de brondata kunnen belanghebbenden – zoals personen van wie de data wordt opgeslagen en onafhankelijke experts – deze niet onderzoeken op mogelijke afwijkingen. Hierdoor is de evaluatie van data die worden gebruikt voor besluitvormingsprocessen en het trainen van AI-systemen afhankelijk van een kleine groep experts. Als evaluatie door deze kleine groep niet zorgvuldig wordt uitgevoerd, kan dit onwenselijke gevolgen hebben, zoals slechte datakwaliteit en vooringenomenheid. Dit schaadt het publieke vertrouwen in technologie en in de organisaties die deze digitale methoden inzetten.
Synthetische data generatie (SDG) biedt een oplossing. Door artificiële data te creëren die de eigenschappen van de originele dataset nabootst zonder daarbij persoonsgegevens te delen, maakt SDG het breder delen van data mogelijk. Het wordt beschouwd als een veilige aanpak voor het breder delen van data, omdat het geen naar individuen herleidbare data bevat. In beneden bijgevoegde memo kan meer achtergrondinformatie worden gevonden over de juridische aspecten van synthetische data generatie.
Voor twee redenen is gebruik van synthetische data lange tijd geremd:
- Privacyrisico’s – Voornamelijk onder juristen bestonden zorgen over de risico’s dat bij het delen van synthetische data alsnog persoonsgegevens vrij zouden komen. Onderzoek en praktijkvoorbeelden hebben aangetoond dat deze risico’s kunnen worden uitgesloten. Zie ook beneden bijgevoegde memo met meer achtergrondinformatie over de juridische aspecten van synthetische data generatie.
- Cloud-afhankelijkheden – Veel bestaande (commerciële) API’s zijn afhankelijk van cloudgebaseerde software, wat ze ongeschikt maakt voor publieke organisaties omdat data van burgers niet zo maar naar cloudplatformen geupload mogen worden. Local-only dataverwerking biedt een oplossing voor dit probleem. Met behulp van deze tool kan synthetische data kan in de browser synthetische data worden gegenereerd. De data verlaat de computer van de gebruiker en dus ook de omgeving van organisatie dus niet.
Kortom, recent use cases hebben laten zien dat synthetische data veilig gedeeld kunnen worden en dat synthetische data gegenereerd kan worden zonder tussenkomst van een cloudprovider. Het is tijd voor opschaling, zodat betrokkenen meer en beter inzicht krijgen op data die overheidsorganisaties van hen beheren.
Toepassingen
Lighthouse Reports heeft onbedoeld verkregen data middels synthetische data publiekelijk kunnen delen, waarmee bias in een dataset van de Gemeente Rotterdam aan het licht is gebracht. Deze dataset werd gebruikt voor machine learning-gedreven risicoprofilering in het kader van heronderzoek naar de bijstandsuitkering.
AI-verordening
Daarnaast bevat Artikel 10(5) van de AI-verordening een specifieke bepaling over het gebruik van synthetische data voor biasdetectie en -mitigatie. Het vereist dat aanbieders van AI-systemen bias eerst onderzoeken met behulp van synthetische- of geanonimiseerde data, in plaats van direct “bijzondere categorieën persoonsgegevens te verwerken”.
Wat is local-only?
Local-only is het tegenovergestelde van cloud computing: de data wordt niet geüpload naar derden, zoals cloudproviders, en wordt verwerkt door je eigen computer. De data die aan de tool wordt gekoppeld, verlaat je computer of de omgeving van je organisatie dus niet. De tool is privacyvriendelijk omdat de data binnen bestaande bevoegdheden verwerkt kan worden en niet gedeeld hoeft te worden met nieuwe partijen. De unsupervised bias detectie tool kan ook lokaal binnen je organisatie worden gehost. Instructies, inclusief de broncode van de tool, zijn te vinden op Github.
Overzicht van local-only architectuur
Explainer – Local-only tools voor AI validatie
Deze local-only synthetische data generatie tool is ontwikkeld met steun van publieke en filantropische organisaties.

Innovatiebudget Ministerie van Binnenlandse Zaken
Beschrijving
In samenwerking met de Dienst Uitvoering Onderwijs (DUO) en het Ministerie van Binnenlandse Zaken heeft Algorithm Audit deze tool ontwikkeld en getest in de periode juli 2024 tot juli 2025 met ondersteuning van Innovatiebudget, een jaarlijkse competitie georganiseerd door het Ministerie van Binnenlandse Zaken. De voortgang van het project werd gedeeld tijdens een bijeenkomst op 13-02-2025. Een eerste versie van de tools zijn tijdens een webinar online gelanceerd op 10-06-2025.


SIDN Fonds
Beschrijving
In 2024 ondersteunde het SIDN Fonds Algorithm Audit bij het ontwikkelen van een eerste demo van de synthetische data generatie tool.


